ARFS - Customizing GrootCV#
GrootCV allows users to customize certain parameters when using the lightGBM algorithm in Python. However, it’s essential to be aware that some of these parameters will be automatically adjusted by the algorithm itself. Specifically, the overridden parameters are objective, verbose, is_balanced, and n_iterations.
[1]:
# from IPython.core.display import display, HTML
# display(HTML("<style>.container { width:95% !important; }</style>"))
import time
import numpy as np
import matplotlib.pyplot as plt
import arfs
from arfs.feature_selection import GrootCV
from arfs.utils import load_data
from arfs.benchmark import highlight_tick
rng = np.random.RandomState(seed=42)
# import warnings
# warnings.filterwarnings('ignore')
[2]:
import os
import multiprocessing
def get_physical_cores():
if os.name == "posix": # For Unix-based systems (e.g., Linux, macOS)
try:
return os.sysconf("SC_NPROCESSORS_ONLN")
except ValueError:
pass
elif os.name == "nt": # For Windows
try:
return int(os.environ["NUMBER_OF_PROCESSORS"])
except (ValueError, KeyError):
pass
return multiprocessing.cpu_count()
num_physical_cores = get_physical_cores()
print(f"Number of physical cores: {num_physical_cores}")
Number of physical cores: 4
[3]:
print(f"Run with ARFS {arfs.__version__}")
Run with ARFS 3.0.0
[4]:
boston = load_data(name="Boston")
X, y = boston.data, boston.target
[5]:
X.dtypes
[5]:
CRIM float64
ZN float64
INDUS float64
CHAS category
NOX float64
RM float64
AGE float64
DIS float64
RAD category
TAX float64
PTRATIO float64
B float64
LSTAT float64
random_num1 float64
random_num2 int32
random_cat category
random_cat_2 category
genuine_num float64
dtype: object
[6]:
X.head()
[6]:
| CRIM | ZN | INDUS | CHAS | NOX | RM | AGE | DIS | RAD | TAX | PTRATIO | B | LSTAT | random_num1 | random_num2 | random_cat | random_cat_2 | genuine_num | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.00632 | 18.0 | 2.31 | 0.0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1.0 | 296.0 | 15.3 | 396.90 | 4.98 | 0.496714 | 0 | cat_3517 | Platist | 7.080332 |
| 1 | 0.02731 | 0.0 | 7.07 | 0.0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2.0 | 242.0 | 17.8 | 396.90 | 9.14 | -0.138264 | 0 | cat_2397 | MarkZ | 5.245384 |
| 2 | 0.02729 | 0.0 | 7.07 | 0.0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2.0 | 242.0 | 17.8 | 392.83 | 4.03 | 0.647689 | 0 | cat_3735 | Dracula | 6.375795 |
| 3 | 0.03237 | 0.0 | 2.18 | 0.0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3.0 | 222.0 | 18.7 | 394.63 | 2.94 | 1.523030 | 0 | cat_2870 | Bejita | 6.725118 |
| 4 | 0.06905 | 0.0 | 2.18 | 0.0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3.0 | 222.0 | 18.7 | 396.90 | 5.33 | -0.234153 | 4 | cat_1160 | Variance | 7.867781 |
Number of processes#
For optimal performance on CPUs, set the n_jobs parameter to match the number of physical cores available on your machine. Keep in mind that using n_jobs=0 will use the default number of threads in OpenMP, and running multiple processes might not always yield faster results due to the overhead involved in initiating those processes.
[7]:
for n_jobs in range(num_physical_cores):
start_time = time.time()
feat_selector = GrootCV(
objective="rmse",
cutoff=1,
n_folds=5,
n_iter=5,
silent=True,
fastshap=False,
n_jobs=n_jobs,
)
feat_selector.fit(X, y, sample_weight=None)
end_time = time.time()
execution_time = end_time - start_time
print(f"n_jobs = {n_jobs}, Execution time: {execution_time:.3f} seconds")
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[238] training's l2: 0.224881 valid_1's l2: 12.6928
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[412] training's l2: 0.0381449 valid_1's l2: 10.5172
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[52] training's l2: 2.45293 valid_1's l2: 8.55685
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[55] training's l2: 2.03526 valid_1's l2: 8.125
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[52] training's l2: 2.9843 valid_1's l2: 13.4019
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[78] training's l2: 1.35125 valid_1's l2: 12.4942
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[234] training's l2: 0.144527 valid_1's l2: 10.9799
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[227] training's l2: 0.114625 valid_1's l2: 11.3945
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[110] training's l2: 0.700409 valid_1's l2: 9.77917
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[229] training's l2: 0.111861 valid_1's l2: 7.52847
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[44] training's l2: 3.13271 valid_1's l2: 10.5874
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[328] training's l2: 0.0248466 valid_1's l2: 10.3883
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[110] training's l2: 0.453739 valid_1's l2: 17.2555
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[79] training's l2: 1.25168 valid_1's l2: 9.59104
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[177] training's l2: 0.27132 valid_1's l2: 7.54623
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[486] training's l2: 0.0222516 valid_1's l2: 11.9391
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[145] training's l2: 0.418426 valid_1's l2: 13.6506
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[38] training's l2: 3.56361 valid_1's l2: 9.26995
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[243] training's l2: 0.234916 valid_1's l2: 8.68421
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[39] training's l2: 3.51271 valid_1's l2: 9.71386
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[133] training's l2: 0.585123 valid_1's l2: 9.29017
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[151] training's l2: 0.396861 valid_1's l2: 6.23042
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[487] training's l2: 0.0443864 valid_1's l2: 10.1834
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[101] training's l2: 0.882552 valid_1's l2: 10.2793
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[142] training's l2: 0.378955 valid_1's l2: 11.171
n_jobs = 0, Execution time: 20.513 seconds
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[190] training's l2: 0.273856 valid_1's l2: 14.3231
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[217] training's l2: 0.180005 valid_1's l2: 11.3392
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[125] training's l2: 0.450836 valid_1's l2: 6.85037
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[89] training's l2: 1.03346 valid_1's l2: 8.02004
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[127] training's l2: 0.900129 valid_1's l2: 12.1425
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[112] training's l2: 0.830825 valid_1's l2: 11.5098
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[96] training's l2: 1.03554 valid_1's l2: 11.1675
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[45] training's l2: 3.42039 valid_1's l2: 12.692
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[310] training's l2: 0.106466 valid_1's l2: 9.19877
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[66] training's l2: 1.54931 valid_1's l2: 8.04193
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[53] training's l2: 2.31115 valid_1's l2: 10.9018
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[303] training's l2: 0.0359209 valid_1's l2: 9.4029
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[99] training's l2: 0.525439 valid_1's l2: 17.8515
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[120] training's l2: 0.67681 valid_1's l2: 9.59287
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[109] training's l2: 0.908529 valid_1's l2: 8.44148
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[311] training's l2: 0.0934937 valid_1's l2: 11.791
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[163] training's l2: 0.243307 valid_1's l2: 13.7383
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[56] training's l2: 2.11714 valid_1's l2: 9.09525
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[243] training's l2: 0.176262 valid_1's l2: 8.41932
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[81] training's l2: 1.21692 valid_1's l2: 9.35191
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[150] training's l2: 0.426636 valid_1's l2: 9.03371
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[163] training's l2: 0.28266 valid_1's l2: 5.54949
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[381] training's l2: 0.0844868 valid_1's l2: 10.8546
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[90] training's l2: 1.13239 valid_1's l2: 10.7036
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[312] training's l2: 0.0692601 valid_1's l2: 9.75267
n_jobs = 1, Execution time: 21.413 seconds
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[218] training's l2: 0.254215 valid_1's l2: 12.1184
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[98] training's l2: 0.879983 valid_1's l2: 11.9147
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[115] training's l2: 0.649494 valid_1's l2: 7.57114
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[56] training's l2: 1.97842 valid_1's l2: 7.59178
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[153] training's l2: 0.510117 valid_1's l2: 11.9023
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[97] training's l2: 0.921518 valid_1's l2: 11.2244
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[120] training's l2: 0.619522 valid_1's l2: 10.9341
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[173] training's l2: 0.279307 valid_1's l2: 11.271
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[108] training's l2: 0.826137 valid_1's l2: 10.5644
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[173] training's l2: 0.266505 valid_1's l2: 6.75991
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[43] training's l2: 3.10855 valid_1's l2: 10.0525
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[227] training's l2: 0.111835 valid_1's l2: 9.7899
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[101] training's l2: 0.616808 valid_1's l2: 17.3979
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[124] training's l2: 0.656719 valid_1's l2: 10.6264
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[92] training's l2: 1.30396 valid_1's l2: 9.67713
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[162] training's l2: 0.638165 valid_1's l2: 12.0467
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[68] training's l2: 1.64348 valid_1's l2: 13.6765
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[76] training's l2: 1.46197 valid_1's l2: 9.57482
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[195] training's l2: 0.370436 valid_1's l2: 8.3644
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[105] training's l2: 0.750469 valid_1's l2: 8.4477
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[114] training's l2: 0.723268 valid_1's l2: 9.00775
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[165] training's l2: 0.383124 valid_1's l2: 5.35926
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[381] training's l2: 0.0762215 valid_1's l2: 11.0566
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[39] training's l2: 3.6599 valid_1's l2: 13.03
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[163] training's l2: 0.277427 valid_1's l2: 10.8601
n_jobs = 2, Execution time: 13.366 seconds
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[629] training's l2: 0.014629 valid_1's l2: 10.847
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[588] training's l2: 0.0111335 valid_1's l2: 9.98149
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[94] training's l2: 0.963572 valid_1's l2: 8.25305
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[92] training's l2: 0.939846 valid_1's l2: 8.82814
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[42] training's l2: 3.81345 valid_1's l2: 13.5729
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[82] training's l2: 1.28497 valid_1's l2: 11.6207
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[126] training's l2: 0.654048 valid_1's l2: 11.0766
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[134] training's l2: 0.533755 valid_1's l2: 12.7036
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[136] training's l2: 0.577568 valid_1's l2: 9.14795
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[108] training's l2: 0.780878 valid_1's l2: 8.10059
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[44] training's l2: 3.23893 valid_1's l2: 9.9466
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[311] training's l2: 0.021056 valid_1's l2: 9.46753
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[71] training's l2: 1.26025 valid_1's l2: 18.0702
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[345] training's l2: 0.0242577 valid_1's l2: 9.49228
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[165] training's l2: 0.371359 valid_1's l2: 8.12137
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[129] training's l2: 0.915369 valid_1's l2: 12.3901
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[134] training's l2: 0.405385 valid_1's l2: 14.1637
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[58] training's l2: 2.1152 valid_1's l2: 9.0799
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[240] training's l2: 0.204107 valid_1's l2: 9.34156
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[53] training's l2: 2.45332 valid_1's l2: 9.93933
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[99] training's l2: 1.15387 valid_1's l2: 10.0336
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[155] training's l2: 0.430912 valid_1's l2: 5.7752
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[616] training's l2: 0.0220885 valid_1's l2: 11.4859
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[55] training's l2: 2.46709 valid_1's l2: 12.4691
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[165] training's l2: 0.26547 valid_1's l2: 9.38023
n_jobs = 3, Execution time: 17.489 seconds
Regularization#
By default, GrootCV is using crossvalidation and early-stopping to prevent overfitting and to ensure the robustness of the feature selection. However, if you want to prevent overfitting even more, you can use the dedicated lightgbm parameters such as min_data_in_leaf.
Let’s illustrate: - less regularization than default - default regularization ({"min_data_in_leaf": 20}) - larger regularization
[8]:
# GrootCV with less regularization
feat_selector = GrootCV(
objective="rmse",
cutoff=1,
n_folds=5,
n_iter=5,
silent=True,
fastshap=False,
n_jobs=0,
lgbm_params={"min_data_in_leaf": 10},
)
feat_selector.fit(X, y, sample_weight=None)
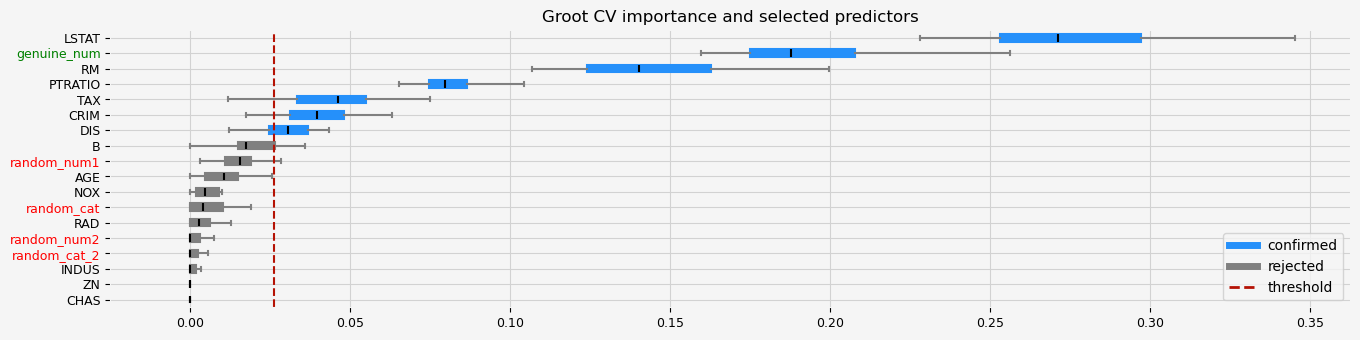
print(f"The selected features: {feat_selector.get_feature_names_out()}")
print(f"The agnostic ranking: {feat_selector.ranking_}")
print(f"The naive ranking: {feat_selector.ranking_absolutes_}")
fig = feat_selector.plot_importance(n_feat_per_inch=5)
# highlight synthetic random variable
fig = highlight_tick(figure=fig, str_match="random")
fig = highlight_tick(figure=fig, str_match="genuine", color="green")
plt.show()
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[111] training's l2: 0.134988 valid_1's l2: 12.9829
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[49] training's l2: 0.681485 valid_1's l2: 10.1274
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[55] training's l2: 0.362196 valid_1's l2: 7.86925
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[108] training's l2: 0.0227306 valid_1's l2: 7.63047
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[96] training's l2: 0.176277 valid_1's l2: 11.8806
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[89] training's l2: 0.134046 valid_1's l2: 9.73156
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[51] training's l2: 0.576899 valid_1's l2: 12.3213
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[155] training's l2: 0.0475877 valid_1's l2: 11.3682
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[100] training's l2: 0.143347 valid_1's l2: 9.06797
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[33] training's l2: 1.18325 valid_1's l2: 6.64211
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[51] training's l2: 0.558983 valid_1's l2: 7.71448
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[73] training's l2: 0.229031 valid_1's l2: 10.3417
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[102] training's l2: 0.0801505 valid_1's l2: 17.6877
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[121] training's l2: 0.0316495 valid_1's l2: 11.1541
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[42] training's l2: 0.754753 valid_1's l2: 9.01101
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[155] training's l2: 0.0784777 valid_1's l2: 11.1948
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[102] training's l2: 0.155993 valid_1's l2: 13.4692
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[68] training's l2: 0.174167 valid_1's l2: 8.59246
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[106] training's l2: 0.0701699 valid_1's l2: 9.6467
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[76] training's l2: 0.122532 valid_1's l2: 8.97286
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[164] training's l2: 0.0250354 valid_1's l2: 8.51338
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[118] training's l2: 0.0242659 valid_1's l2: 6.47121
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[178] training's l2: 0.0566502 valid_1's l2: 10.4353
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[48] training's l2: 0.513445 valid_1's l2: 10.241
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[155] training's l2: 0.034064 valid_1's l2: 10.9082
The selected features: ['CRIM' 'NOX' 'RM' 'AGE' 'DIS' 'TAX' 'PTRATIO' 'B' 'LSTAT' 'genuine_num']
The agnostic ranking: [2 1 1 1 2 2 2 2 1 2 2 2 2 1 1 1 1 2]
The naive ranking: ['LSTAT', 'RM', 'PTRATIO', 'DIS', 'NOX', 'CRIM', 'AGE', 'B', 'INDUS', 'ShadowVar14', 'ShadowVar1', 'ShadowVar12', 'ShadowVar13', 'ShadowVar11', 'ShadowVar10', 'RAD', 'ShadowVar15', 'CHAS']
[9]:
# GrootCV with default regularization
feat_selector = GrootCV(
objective="rmse",
cutoff=1,
n_folds=5,
n_iter=5,
silent=True,
fastshap=False,
n_jobs=0,
lgbm_params=None,
)
feat_selector.fit(X, y, sample_weight=None)
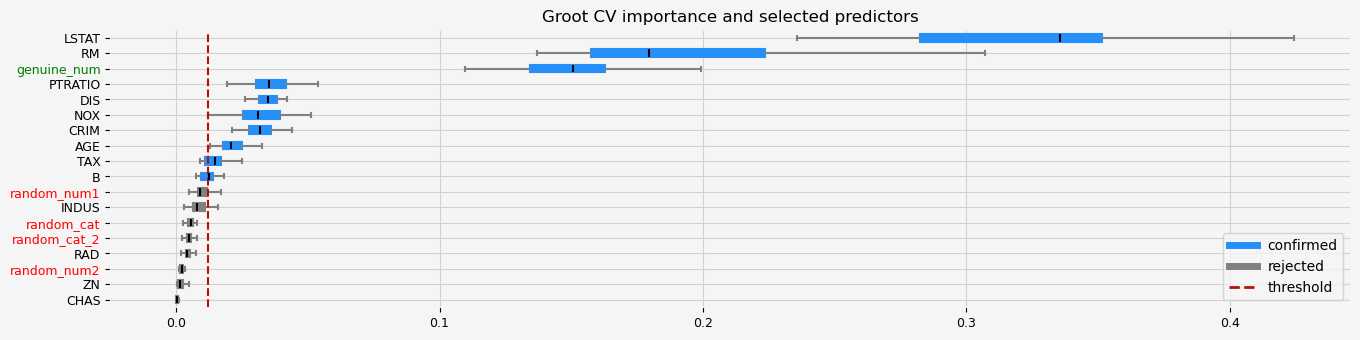
print(f"The selected features: {feat_selector.get_feature_names_out()}")
print(f"The agnostic ranking: {feat_selector.ranking_}")
print(f"The naive ranking: {feat_selector.ranking_absolutes_}")
fig = feat_selector.plot_importance(n_feat_per_inch=5)
# highlight synthetic random variable
fig = highlight_tick(figure=fig, str_match="random")
fig = highlight_tick(figure=fig, str_match="genuine", color="green")
plt.show()
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[204] training's l2: 0.328399 valid_1's l2: 12.6374
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[1717] training's l2: 3.09988e-05 valid_1's l2: 9.89188
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[48] training's l2: 2.77439 valid_1's l2: 8.91405
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[78] training's l2: 1.23117 valid_1's l2: 8.03399
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[128] training's l2: 0.832015 valid_1's l2: 12.4074
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[61] training's l2: 1.80312 valid_1's l2: 12.8799
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[81] training's l2: 1.44872 valid_1's l2: 11.0638
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[395] training's l2: 0.00826615 valid_1's l2: 11.4471
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[131] training's l2: 0.567405 valid_1's l2: 9.64762
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[115] training's l2: 0.638808 valid_1's l2: 8.73057
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[44] training's l2: 2.96421 valid_1's l2: 10.4865
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[252] training's l2: 0.0678433 valid_1's l2: 9.74184
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[127] training's l2: 0.310259 valid_1's l2: 18.4646
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[137] training's l2: 0.41149 valid_1's l2: 10.2382
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[41] training's l2: 3.80887 valid_1's l2: 9.21062
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[288] training's l2: 0.163069 valid_1's l2: 13.3802
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[49] training's l2: 2.40209 valid_1's l2: 14.5785
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[44] training's l2: 3.00934 valid_1's l2: 8.91018
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[235] training's l2: 0.206091 valid_1's l2: 8.12457
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[75] training's l2: 1.50937 valid_1's l2: 9.6955
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[326] training's l2: 0.017907 valid_1's l2: 9.50508
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[129] training's l2: 0.448851 valid_1's l2: 5.25769
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[248] training's l2: 0.182668 valid_1's l2: 11.801
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[81] training's l2: 1.31323 valid_1's l2: 12.093
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[316] training's l2: 0.0658644 valid_1's l2: 9.64286
The selected features: ['CRIM' 'NOX' 'RM' 'AGE' 'DIS' 'TAX' 'PTRATIO' 'LSTAT' 'genuine_num']
The agnostic ranking: [2 1 1 1 2 2 2 2 1 2 2 1 2 1 1 1 1 2]
The naive ranking: ['LSTAT', 'RM', 'PTRATIO', 'DIS', 'NOX', 'CRIM', 'AGE', 'B', 'ShadowVar1', 'ShadowVar13', 'INDUS', 'ShadowVar12', 'ShadowVar14', 'ShadowVar11', 'ShadowVar10', 'RAD', 'ShadowVar15', 'CHAS']
[10]:
# GrootCV with larger regularization
feat_selector = GrootCV(
objective="rmse",
cutoff=1,
n_folds=5,
n_iter=5,
silent=True,
fastshap=False,
n_jobs=0,
lgbm_params={"min_data_in_leaf": 100},
)
feat_selector.fit(X, y, sample_weight=None)
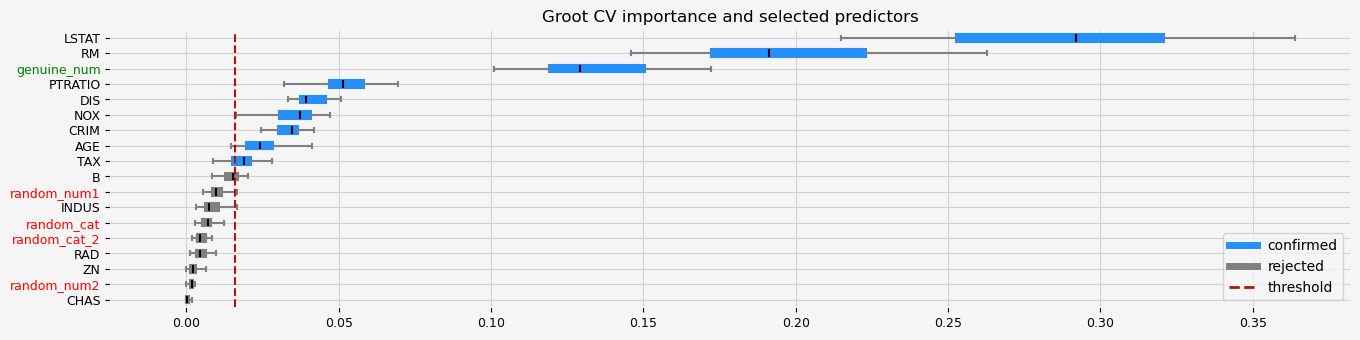
print(f"The selected features: {feat_selector.get_feature_names_out()}")
print(f"The agnostic ranking: {feat_selector.ranking_}")
print(f"The naive ranking: {feat_selector.ranking_absolutes_}")
fig = feat_selector.plot_importance(n_feat_per_inch=5)
# highlight synthetic random variable
fig = highlight_tick(figure=fig, str_match="random")
fig = highlight_tick(figure=fig, str_match="genuine", color="green")
plt.show()
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[146] training's l2: 14.0206 valid_1's l2: 25.4565
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[74] training's l2: 16.4327 valid_1's l2: 27.9672
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[51] training's l2: 20.0441 valid_1's l2: 20.4755
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[131] training's l2: 15.3755 valid_1's l2: 18.3163
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[97] training's l2: 16.3584 valid_1's l2: 22.9324
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[101] training's l2: 15.8421 valid_1's l2: 26.4306
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[116] training's l2: 16.3034 valid_1's l2: 22.1835
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[92] training's l2: 16.8246 valid_1's l2: 21.3065
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[44] training's l2: 18.7732 valid_1's l2: 25.5127
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[84] training's l2: 18.0544 valid_1's l2: 16.4981
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[86] training's l2: 17.9334 valid_1's l2: 18.3251
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[111] training's l2: 15.5826 valid_1's l2: 26.2426
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[81] training's l2: 15.3025 valid_1's l2: 28.8493
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[111] training's l2: 15.5484 valid_1's l2: 24.8517
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[124] training's l2: 15.6684 valid_1's l2: 13.8493
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[72] training's l2: 17.6773 valid_1's l2: 22.8144
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[59] training's l2: 18.4897 valid_1's l2: 24.7653
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[199] training's l2: 12.8833 valid_1's l2: 19.6554
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[139] training's l2: 13.8401 valid_1's l2: 28.159
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[65] training's l2: 18.8797 valid_1's l2: 16.7961
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[156] training's l2: 13.4741 valid_1's l2: 25.9086
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[160] training's l2: 13.8505 valid_1's l2: 18.4398
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[64] training's l2: 17.5861 valid_1's l2: 23.6619
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[124] training's l2: 16.4766 valid_1's l2: 17.9721
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[90] training's l2: 15.9478 valid_1's l2: 23.7916
The selected features: ['CRIM' 'RM' 'DIS' 'TAX' 'PTRATIO' 'LSTAT' 'genuine_num']
The agnostic ranking: [2 1 1 1 1 2 1 2 1 2 2 1 2 1 1 1 1 2]
The naive ranking: ['LSTAT', 'RM', 'PTRATIO', 'CRIM', 'DIS', 'B', 'AGE', 'ShadowVar11', 'ShadowVar12', 'ShadowVar14', 'NOX', 'ShadowVar1', 'ShadowVar13', 'ShadowVar10', 'RAD', 'ShadowVar15', 'INDUS', 'CHAS']