ARFS - Is collinearity harmul?#
As I’ll show, collinearity is harmful. All relevant feature selection methods are not 100% robust when the data have a strong correlation structure. Many (most) feature selection schemes suffer from collinearity.
[2]:
# from IPython.core.display import display, HTML
# display(HTML("<style>.container { width:95% !important; }</style>"))
import catboost
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import gc
import shap
from boruta import BorutaPy as bp
from sklearn.datasets import fetch_openml
from sklearn.inspection import permutation_importance
from sklearn.pipeline import Pipeline
from sklearn.datasets import fetch_openml
from sklearn.inspection import permutation_importance
from sklearn.base import clone
from sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
from lightgbm import LGBMRegressor, LGBMClassifier
from xgboost import XGBRegressor, XGBClassifier
from catboost import CatBoostRegressor, CatBoostClassifier
from sys import getsizeof, path
import arfs
import arfs.feature_selection as arfsfs
import arfs.feature_selection.allrelevant as arfsgroot
from arfs.utils import LightForestClassifier, LightForestRegressor
from arfs.benchmark import highlight_tick, compare_varimp, sklearn_pimp_bench
from arfs.utils import load_data
rng = np.random.RandomState(seed=42)
# import warnings
# warnings.filterwarnings('ignore')
[3]:
print(f"Run with ARFS {arfs.__version__}")
Run with ARFS 3.0.0
[4]:
gc.enable()
gc.collect()
[4]:
0
Simple Usage#
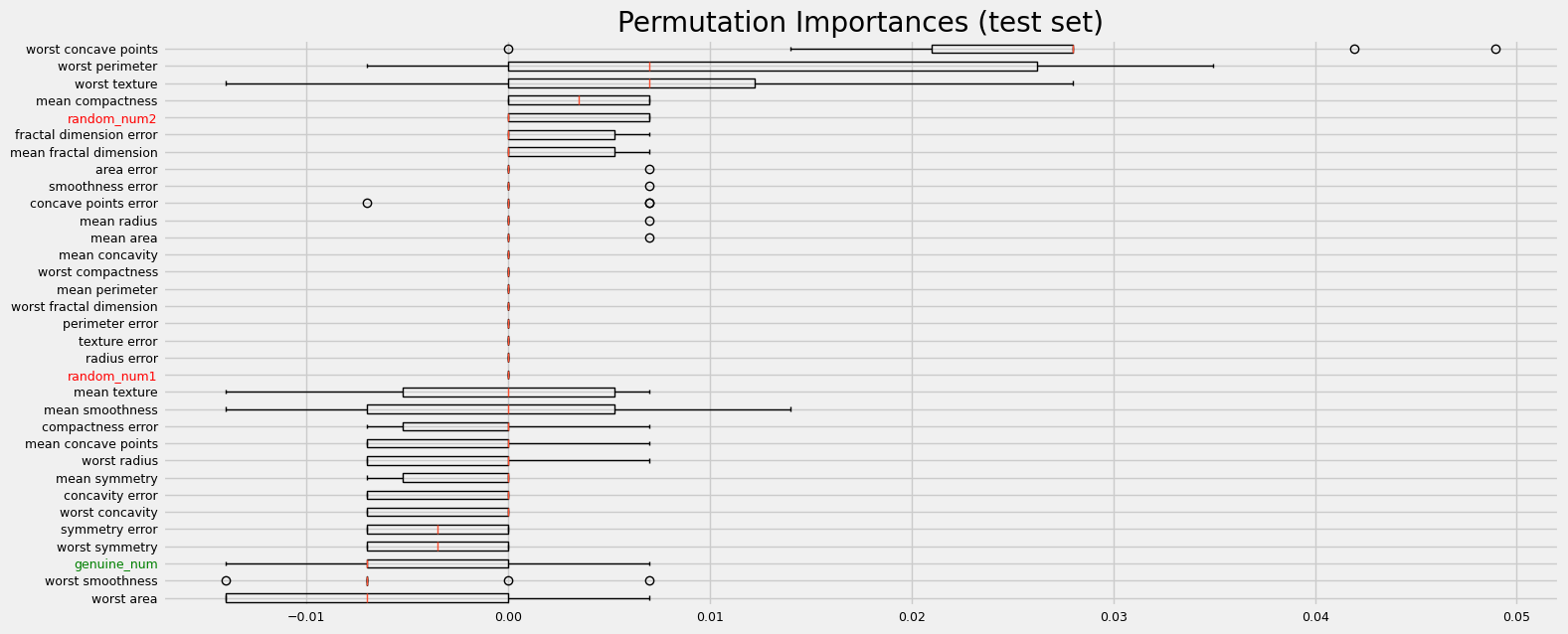
If the dataset contains multicollinear features, the permutation importance will show that none of the features are important. This is obviously a drawback. Let’s illustrate how the different ARFS methods deal with collinearity and if the performance depends on the kind of feature importance (native, shap, pimp).
For comparison purpose, I reproduce below the scikit-learn example, with added random predictors (which should be filtered out).
I’ll compare to the performance when collinear features are removed, using the pre-filters included in the package. When the filter finds collinear feature, it will keep one of them, randomly chosen, which is ok since it carries the same information than the others.
[5]:
cancer = load_data(name="cancer")
X, y = cancer.data, cancer.target
# New instance of the class
# unsupervised learning, doesn't need a target
selector = arfsfs.CollinearityThreshold(threshold=0.75)
X_filtered = selector.fit_transform(X)
print(f"The features going in the selector are : {selector.feature_names_in_}")
print(f"The support is : {selector.support_}")
print(f"The selected features are : {selector.get_feature_names_out()}")
fig = selector.plot_association()
The features going in the selector are : ['mean radius' 'mean texture' 'mean perimeter' 'mean area'
'mean smoothness' 'mean compactness' 'mean concavity'
'mean concave points' 'mean symmetry' 'mean fractal dimension'
'radius error' 'texture error' 'perimeter error' 'area error'
'smoothness error' 'compactness error' 'concavity error'
'concave points error' 'symmetry error' 'fractal dimension error'
'worst radius' 'worst texture' 'worst perimeter' 'worst area'
'worst smoothness' 'worst compactness' 'worst concavity'
'worst concave points' 'worst symmetry' 'worst fractal dimension'
'random_num1' 'random_num2' 'genuine_num']
The support is : [False True False True False False False False True False False True
False True True False True False True True False False False False
True False False False True True True True True]
The selected features are : ['mean texture' 'mean area' 'mean symmetry' 'texture error' 'area error'
'smoothness error' 'concavity error' 'symmetry error'
'fractal dimension error' 'worst smoothness' 'worst symmetry'
'worst fractal dimension' 'random_num1' 'random_num2' 'genuine_num']

[6]:
X_filtered.head()
[6]:
| mean texture | mean area | mean symmetry | texture error | area error | smoothness error | concavity error | symmetry error | fractal dimension error | worst smoothness | worst symmetry | worst fractal dimension | random_num1 | random_num2 | genuine_num | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 10.38 | 1001.0 | 0.2419 | 0.9053 | 153.40 | 0.006399 | 0.05373 | 0.03003 | 0.006193 | 0.1622 | 0.4601 | 0.11890 | 0.496714 | 0 | -0.249340 |
| 1 | 17.77 | 1326.0 | 0.1812 | 0.7339 | 74.08 | 0.005225 | 0.01860 | 0.01389 | 0.003532 | 0.1238 | 0.2750 | 0.08902 | -0.138264 | 1 | -0.044410 |
| 2 | 21.25 | 1203.0 | 0.2069 | 0.7869 | 94.03 | 0.006150 | 0.03832 | 0.02250 | 0.004571 | 0.1444 | 0.3613 | 0.08758 | 0.647689 | 3 | 0.128395 |
| 3 | 20.38 | 386.1 | 0.2597 | 1.1560 | 27.23 | 0.009110 | 0.05661 | 0.05963 | 0.009208 | 0.2098 | 0.6638 | 0.17300 | 1.523030 | 0 | -0.079921 |
| 4 | 14.34 | 1297.0 | 0.1809 | 0.7813 | 94.44 | 0.011490 | 0.05688 | 0.01756 | 0.005115 | 0.1374 | 0.2364 | 0.07678 | -0.234153 | 0 | -0.094302 |
Sklearn permutation importance#
The performance is clearly affected by collinearity
[7]:
plt.style.use("fivethirtyeight")
[8]:
%%time
# Let's use lightgbm as booster, see below for using more models
model = LGBMClassifier(random_state=42, verbose=-1)
# Benchmark with scikit-learn permutation importance
print("=" * 20 + " Benchmarking using sklearn permutation importance " + "=" * 20)
fig = sklearn_pimp_bench(model, X, y, task="classification", sample_weight=None)
==================== Benchmarking using sklearn permutation importance ====================
CPU times: user 2.7 s, sys: 252 ms, total: 2.96 s
Wall time: 9.22 s
Let’s repeat the permutation importance but with the collinear predictors filtered out.
[9]:
%%time
# be sure to use the same but non-fitted estimator
model = clone(model)
# Benchmark with scikit-learn permutation importance
print("=" * 20 + " Benchmarking using sklearn permutation importance " + "=" * 20)
fig = sklearn_pimp_bench(
model, X_filtered, y, task="classification", sample_weight=None
)
==================== Benchmarking using sklearn permutation importance ====================

CPU times: user 1.38 s, sys: 149 ms, total: 1.53 s
Wall time: 2.13 s
The permutation importance performance looks much better when collinear predictors are filtered out.
Leshy with permutation importance#
Hereunder, I illustrate that the collinearity is problematic for the three methods of All Relevant Feature Selection. However the stability is greatly improved when the collinearity is handled.
[10]:
%%time
# be sure to use the same but non-fitted estimator
model = clone(model)
# Leshy, all the predictors, no-preprocessing
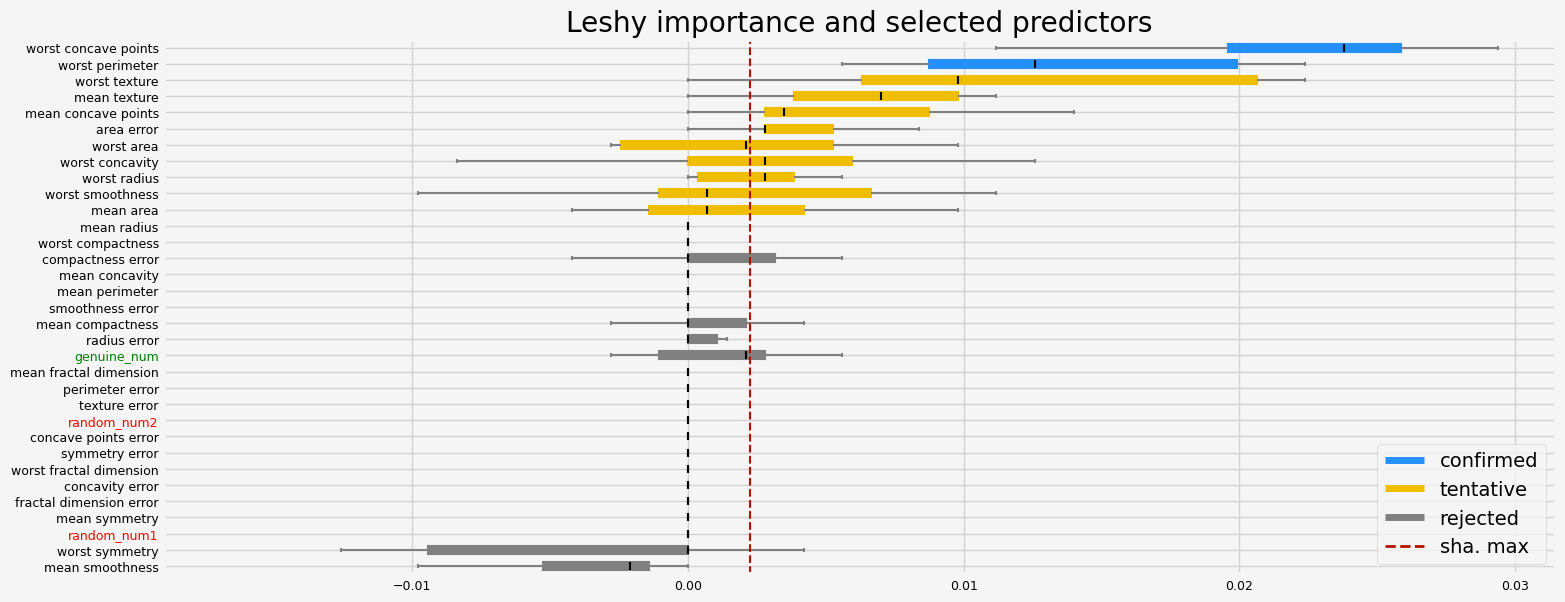
feat_selector = arfsgroot.Leshy(
model, n_estimators=100, verbose=1, max_iter=10, random_state=42, importance="pimp"
)
feat_selector.fit(X, y, sample_weight=None)
print(f"The selected features: {feat_selector.get_feature_names_out()}")
print(f"The agnostic ranking: {feat_selector.ranking_}")
print(f"The naive ranking: {feat_selector.ranking_absolutes_}")
fig = feat_selector.plot_importance(n_feat_per_inch=5)
# highlight synthetic random variable
fig = highlight_tick(figure=fig, str_match="random")
fig = highlight_tick(figure=fig, str_match="genuine", color="green")
plt.show()
Leshy finished running using pimp var. imp.
Iteration: 1 / 10
Confirmed: 2
Tentative: 9
Rejected: 22
All relevant predictors selected in 00:00:27.87
The selected features: ['worst perimeter' 'worst concave points']
The agnostic ranking: [ 3 2 7 2 22 3 3 2 15 7 3 7 15 2 15 15 15 15 15 15 2 2 1 2
15 7 2 1 15 15 21 15 2]
The naive ranking: ['worst concave points', 'worst perimeter', 'worst texture', 'mean texture', 'mean concave points', 'area error', 'worst area', 'worst concavity', 'worst radius', 'worst smoothness', 'mean area', 'mean radius', 'worst compactness', 'compactness error', 'mean concavity', 'mean perimeter', 'smoothness error', 'mean compactness', 'radius error', 'genuine_num', 'mean fractal dimension', 'symmetry error', 'concave points error', 'perimeter error', 'texture error', 'worst fractal dimension', 'random_num2', 'concavity error', 'fractal dimension error', 'mean symmetry', 'random_num1', 'worst symmetry', 'mean smoothness']
CPU times: user 14.5 s, sys: 561 ms, total: 15 s
Wall time: 29 s
Same but collinear predictors filtered out
[11]:
%%time
# be sure to use the same but non-fitted estimator
model = clone(model)
# Leshy, with collinearity handled
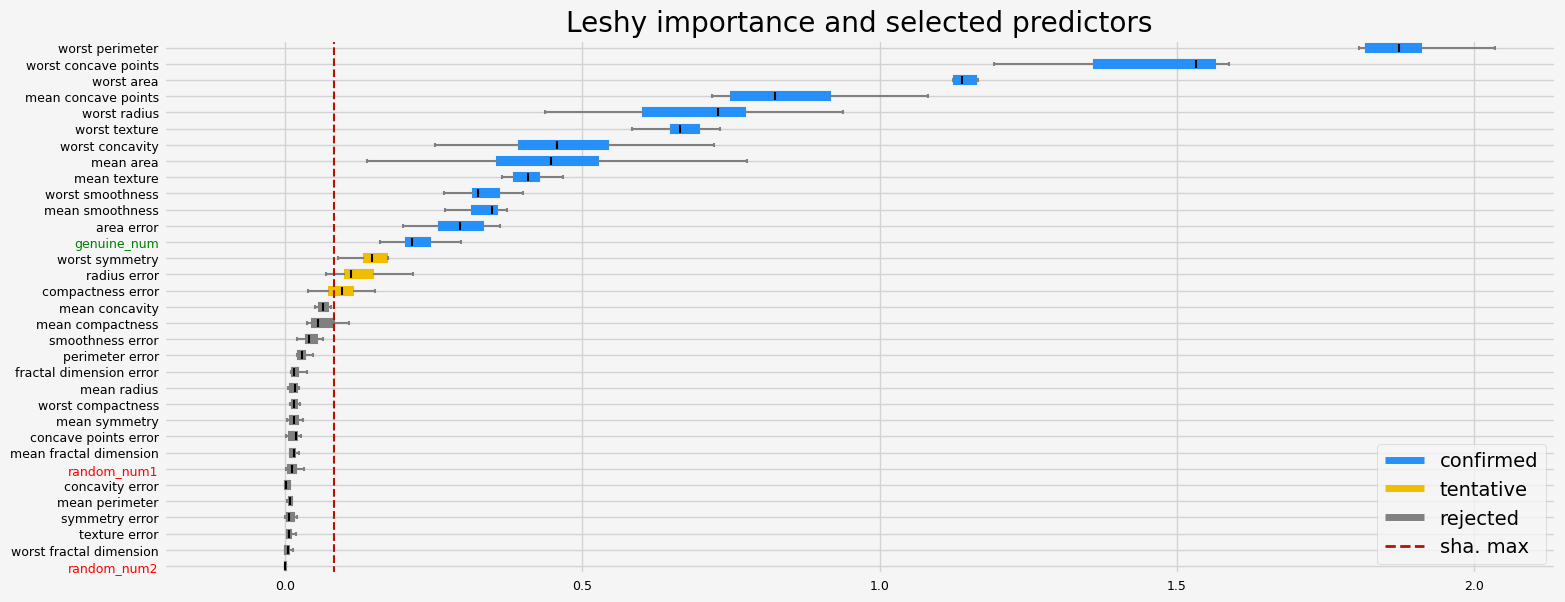
feat_selector = arfsgroot.Leshy(
model, n_estimators=100, verbose=1, max_iter=10, random_state=42, importance="pimp"
)
feat_selector.fit(X_filtered, y, sample_weight=None)
print(f"The selected features: {feat_selector.get_feature_names_out()}")
print(f"The agnostic ranking: {feat_selector.ranking_}")
print(f"The naive ranking: {feat_selector.ranking_absolutes_}")
fig = feat_selector.plot_importance(n_feat_per_inch=5)
# highlight synthetic random variable
fig = highlight_tick(figure=fig, str_match="random")
fig = highlight_tick(figure=fig, str_match="genuine", color="green")
plt.show()
Leshy finished running using pimp var. imp.
Iteration: 1 / 10
Confirmed: 4
Tentative: 3
Rejected: 8
All relevant predictors selected in 00:00:10.04
The selected features: ['mean texture' 'mean area' 'area error' 'worst smoothness']
The agnostic ranking: [1 1 5 2 1 7 2 8 3 1 5 2 3 3 9]
The naive ranking: ['mean area', 'area error', 'worst smoothness', 'mean texture', 'worst fractal dimension', 'texture error', 'concavity error', 'mean symmetry', 'random_num2', 'fractal dimension error', 'random_num1', 'smoothness error', 'genuine_num', 'worst symmetry', 'symmetry error']

CPU times: user 7.55 s, sys: 374 ms, total: 7.93 s
Wall time: 10.5 s
The results are much smoother, smaller variance of the importance.
Does SHAP feature importance suffer from the collinearity?#
SHAP is a linear feature importance attribution, the importance will be split between the collinear features.
With all the predictors#
[ ]:
%%time
# be sure to use the same but non-fitted estimator
model = clone(model)
# Leshy
feat_selector = arfsgroot.Leshy(
model,
n_estimators=100,
verbose=1,
max_iter=10,
random_state=42,
importance="shap",
)
feat_selector.fit(X, y, sample_weight=None)
print(f"The selected features: {feat_selector.get_feature_names_out()}")
print(f"The agnostic ranking: {feat_selector.ranking_}")
print(f"The naive ranking: {feat_selector.ranking_absolutes_}")
fig = feat_selector.plot_importance(n_feat_per_inch=5)
# highlight synthetic random variable
fig = highlight_tick(figure=fig, str_match="random")
fig = highlight_tick(figure=fig, str_match="genuine", color="green")
plt.show()
/home/bsatom/Documents/arfs/src/arfs/feature_selection/allrelevant.py:325: UserWarning: fasttreeshap is not installed. Fallback to shap.
warnings.warn("fasttreeshap is not installed. Fallback to shap.")
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Leshy finished running using shap var. imp.
Iteration: 1 / 10
Confirmed: 13
Tentative: 3
Rejected: 17
All relevant predictors selected in 00:00:05.04
The selected features: ['mean texture' 'mean area' 'mean smoothness' 'mean concave points'
'area error' 'worst radius' 'worst texture' 'worst perimeter'
'worst area' 'worst smoothness' 'worst concavity' 'worst concave points'
'genuine_num']
The agnostic ranking: [ 7 1 15 1 1 4 3 1 13 10 2 16 6 1 5 2 17 10 13 12 1 1 1 1
1 8 1 1 2 17 8 19 1]
The naive ranking: ['worst perimeter', 'worst concave points', 'worst area', 'mean concave points', 'worst radius', 'worst texture', 'worst concavity', 'mean area', 'mean texture', 'worst smoothness', 'mean smoothness', 'area error', 'genuine_num', 'worst symmetry', 'radius error', 'compactness error', 'mean concavity', 'mean compactness', 'smoothness error', 'perimeter error', 'fractal dimension error', 'mean radius', 'worst compactness', 'mean symmetry', 'concave points error', 'mean fractal dimension', 'random_num1', 'concavity error', 'mean perimeter', 'symmetry error', 'texture error', 'worst fractal dimension', 'random_num2']
CPU times: user 8.36 s, sys: 354 ms, total: 8.71 s
Wall time: 5.88 s
With only the filtered predictors#
[13]:
%%time
# be sure to use the same but non-fitted estimator
model = clone(model)
# Leshy
feat_selector = arfsgroot.Leshy(
model,
n_estimators=100,
verbose=1,
max_iter=10,
random_state=42,
importance="shap",
)
feat_selector.fit(X_filtered, y, sample_weight=None)
print(f"The selected features: {feat_selector.get_feature_names_out()}")
print(f"The agnostic ranking: {feat_selector.ranking_}")
print(f"The naive ranking: {feat_selector.ranking_absolutes_}")
fig = feat_selector.plot_importance(n_feat_per_inch=5)
# highlight synthetic random variable
fig = highlight_tick(figure=fig, str_match="random")
fig = highlight_tick(figure=fig, str_match="genuine", color="green")
plt.show()
/home/bsatom/Documents/arfs/src/arfs/feature_selection/allrelevant.py:325: UserWarning: fasttreeshap is not installed. Fallback to shap.
warnings.warn("fasttreeshap is not installed. Fallback to shap.")
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Leshy finished running using shap var. imp.
Iteration: 1 / 10
Confirmed: 8
Tentative: 2
Rejected: 5
All relevant predictors selected in 00:00:02.48
The selected features: ['mean texture' 'mean area' 'area error' 'symmetry error'
'worst smoothness' 'worst symmetry' 'worst fractal dimension'
'genuine_num']
The agnostic ranking: [1 1 5 5 1 2 2 1 3 1 1 1 4 7 1]
The naive ranking: ['mean area', 'area error', 'worst smoothness', 'mean texture', 'genuine_num', 'worst symmetry', 'symmetry error', 'worst fractal dimension', 'concavity error', 'smoothness error', 'fractal dimension error', 'random_num1', 'mean symmetry', 'texture error', 'random_num2']

CPU times: user 4.74 s, sys: 268 ms, total: 5.01 s
Wall time: 2.96 s
There is indeed much less variability in the feature importance when the collinear predictors are filtered out.
BoostAGroota#
All the predictors#
[14]:
%%time
# be sure to use the same but non-fitted estimator
model = clone(model)
model = LGBMClassifier(random_state=42, verbose=-1)
# BoostAGroota
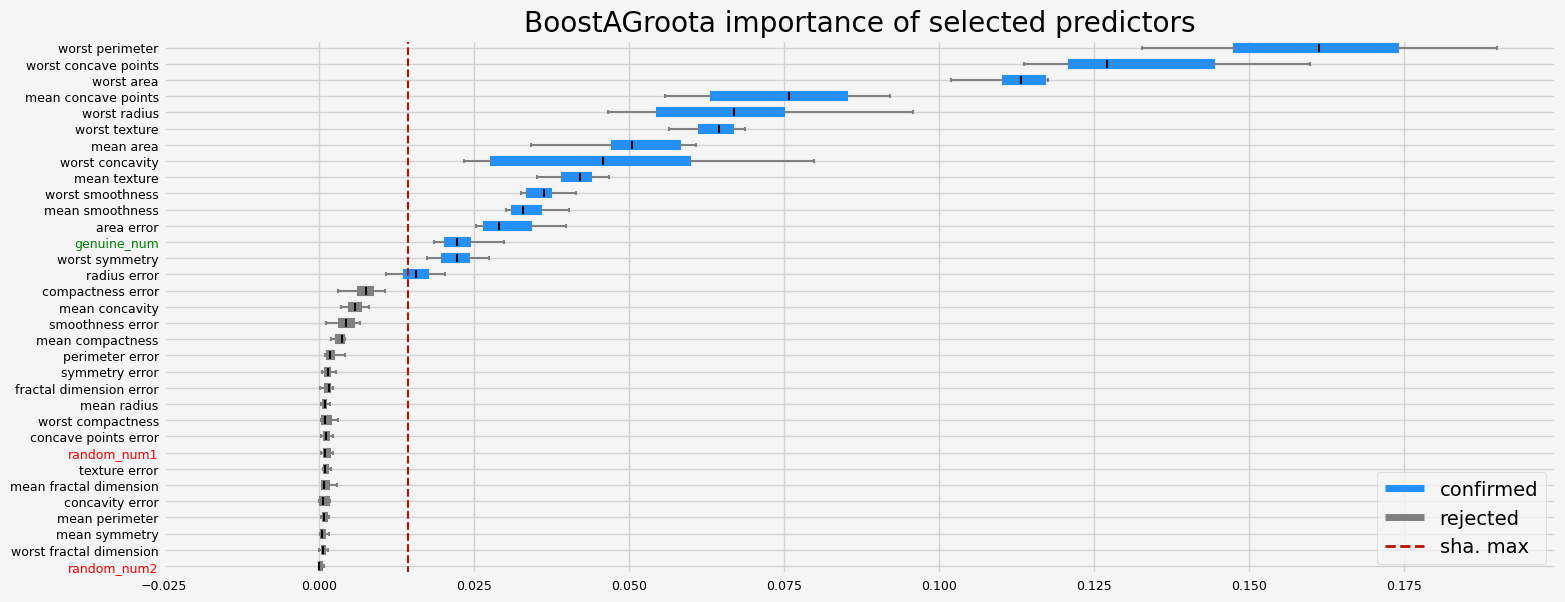
feat_selector = arfsgroot.BoostAGroota(
estimator=model,
cutoff=1,
iters=10,
max_rounds=10,
delta=0.1,
silent=True,
importance="shap",
)
feat_selector.fit(X, y, sample_weight=None)
print(f"The selected features: {feat_selector.get_feature_names_out()}")
print(f"The agnostic ranking: {feat_selector.ranking_}")
print(f"The naive ranking: {feat_selector.ranking_absolutes_}")
fig = feat_selector.plot_importance(n_feat_per_inch=5)
# highlight synthetic random variable
fig = highlight_tick(figure=fig, str_match="random")
fig = highlight_tick(figure=fig, str_match="genuine", color="green")
plt.show()
/home/bsatom/Documents/arfs/src/arfs/feature_selection/allrelevant.py:1556: UserWarning: fasttreeshap is not installed. Fallback to shap.
warnings.warn("fasttreeshap is not installed. Fallback to shap.")
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
The selected features: ['mean texture' 'mean area' 'mean smoothness' 'mean concave points'
'radius error' 'area error' 'worst radius' 'worst texture'
'worst perimeter' 'worst area' 'worst smoothness' 'worst concavity'
'worst concave points' 'worst symmetry' 'genuine_num']
The agnostic ranking: [1 2 1 2 2 1 1 2 1 1 2 1 1 2 1 1 1 1 1 1 2 2 2 2 2 1 2 2 2 1 1 1 2]
The naive ranking: ['worst perimeter', 'worst concave points', 'worst area', 'mean concave points', 'worst radius', 'worst texture', 'mean area', 'worst concavity', 'mean texture', 'worst smoothness', 'mean smoothness', 'area error', 'genuine_num', 'worst symmetry', 'radius error', 'compactness error', 'mean concavity', 'smoothness error', 'mean compactness', 'perimeter error', 'symmetry error', 'fractal dimension error', 'mean radius', 'worst compactness', 'concave points error', 'random_num1', 'texture error', 'mean fractal dimension', 'concavity error', 'mean perimeter', 'mean symmetry', 'worst fractal dimension', 'random_num2']
CPU times: user 11.5 s, sys: 411 ms, total: 11.9 s
Wall time: 6.49 s
Filtered predictors#
[15]:
%%time
# be sure to use the same but non-fitted estimator
model = clone(model)
# BoostAGroota
feat_selector = arfsgroot.BoostAGroota(
estimator=model,
cutoff=1,
iters=10,
max_rounds=10,
delta=0.1,
silent=True,
importance="shap",
)
feat_selector.fit(X_filtered, y, sample_weight=None)
print(f"The selected features: {feat_selector.get_feature_names_out()}")
print(f"The agnostic ranking: {feat_selector.ranking_}")
print(f"The naive ranking: {feat_selector.ranking_absolutes_}")
fig = feat_selector.plot_importance(n_feat_per_inch=5)
# highlight synthetic random variable
fig = highlight_tick(figure=fig, str_match="random")
fig = highlight_tick(figure=fig, str_match="genuine", color="green")
plt.show()
/home/bsatom/Documents/arfs/src/arfs/feature_selection/allrelevant.py:1556: UserWarning: fasttreeshap is not installed. Fallback to shap.
warnings.warn("fasttreeshap is not installed. Fallback to shap.")
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
The selected features: ['mean texture' 'mean area' 'area error' 'symmetry error'
'worst smoothness' 'worst symmetry' 'worst fractal dimension'
'genuine_num']
The agnostic ranking: [2 2 1 1 2 1 1 2 1 2 2 2 1 1 2]
The naive ranking: ['mean area', 'area error', 'worst smoothness', 'mean texture', 'worst symmetry', 'genuine_num', 'symmetry error', 'worst fractal dimension', 'concavity error', 'smoothness error', 'fractal dimension error', 'mean symmetry', 'random_num1', 'texture error', 'random_num2']

CPU times: user 12.5 s, sys: 466 ms, total: 13 s
Wall time: 7.85 s
Same conclusion than for Leshy, the variability is much smaller when the collinear predictors are filtered out.
GrootCV#
All the predictors#
[16]:
%%time
# GrootCV
feat_selector = arfsgroot.GrootCV(
objective="binary", cutoff=1, n_folds=5, n_iter=5, silent=True
)
feat_selector.fit(X, y, sample_weight=None)
print(f"The selected features: {feat_selector.get_feature_names_out()}")
print(f"The agnostic ranking: {feat_selector.ranking_}")
print(f"The naive ranking: {feat_selector.ranking_absolutes_}")
fig = feat_selector.plot_importance(n_feat_per_inch=5)
# highlight synthetic random variable
fig = highlight_tick(figure=fig, str_match="random")
fig = highlight_tick(figure=fig, str_match="genuine", color="green")
plt.show()
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[45] training's binary_logloss: 0.0165973 valid_1's binary_logloss: 0.187039
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[55] training's binary_logloss: 0.00880921 valid_1's binary_logloss: 0.156419
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[65] training's binary_logloss: 0.00453569 valid_1's binary_logloss: 0.080511
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[48] training's binary_logloss: 0.0148767 valid_1's binary_logloss: 0.100268
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[66] training's binary_logloss: 0.0045932 valid_1's binary_logloss: 0.0579635
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[105] training's binary_logloss: 0.000326306 valid_1's binary_logloss: 0.0405374
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[51] training's binary_logloss: 0.0127985 valid_1's binary_logloss: 0.121234
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[51] training's binary_logloss: 0.0116673 valid_1's binary_logloss: 0.0819791
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[38] training's binary_logloss: 0.0296043 valid_1's binary_logloss: 0.0993852
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[30] training's binary_logloss: 0.0468252 valid_1's binary_logloss: 0.171385
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[35] training's binary_logloss: 0.0351786 valid_1's binary_logloss: 0.14495
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[40] training's binary_logloss: 0.029008 valid_1's binary_logloss: 0.0706478
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[342] training's binary_logloss: 4.40698e-06 valid_1's binary_logloss: 0.0257393
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[43] training's binary_logloss: 0.0228276 valid_1's binary_logloss: 0.129049
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[48] training's binary_logloss: 0.014293 valid_1's binary_logloss: 0.153558
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[37] training's binary_logloss: 0.0317493 valid_1's binary_logloss: 0.170896
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[95] training's binary_logloss: 0.00066351 valid_1's binary_logloss: 0.04565
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[70] training's binary_logloss: 0.00328893 valid_1's binary_logloss: 0.0776171
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[50] training's binary_logloss: 0.0124044 valid_1's binary_logloss: 0.119407
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[68] training's binary_logloss: 0.00412237 valid_1's binary_logloss: 0.113319
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[41] training's binary_logloss: 0.0262792 valid_1's binary_logloss: 0.107484
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[49] training's binary_logloss: 0.0124262 valid_1's binary_logloss: 0.140914
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[65] training's binary_logloss: 0.00438094 valid_1's binary_logloss: 0.0764134
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[44] training's binary_logloss: 0.0195379 valid_1's binary_logloss: 0.0827271
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[146] training's binary_logloss: 2.02448e-05 valid_1's binary_logloss: 0.0193166
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
The selected features: ['mean texture' 'mean concave points' 'area error' 'worst radius'
'worst texture' 'worst perimeter' 'worst area' 'worst smoothness'
'worst concavity' 'worst concave points' 'genuine_num']
The agnostic ranking: [1 2 1 1 1 1 1 2 1 1 1 1 1 2 1 1 1 1 1 1 2 2 2 2 2 1 2 2 1 1 1 1 2]
The naive ranking: ['ShadowVar7', 'ShadowVar19', 'ShadowVar31', 'ShadowVar24', 'ShadowVar2', 'ShadowVar14', 'ShadowVar16', 'ShadowVar29', 'ShadowVar1', 'ShadowVar21', 'ShadowVar27', 'ShadowVar18', 'ShadowVar4', 'ShadowVar3', 'ShadowVar28', 'ShadowVar15', 'ShadowVar26', 'ShadowVar12', 'ShadowVar9', 'ShadowVar13', 'ShadowVar5', 'ShadowVar22', 'ShadowVar6', 'ShadowVar30', 'ShadowVar23', 'ShadowVar8', 'ShadowVar33', 'ShadowVar11', 'ShadowVar10', 'ShadowVar25', 'ShadowVar17', 'ShadowVar20', 'ShadowVar32']
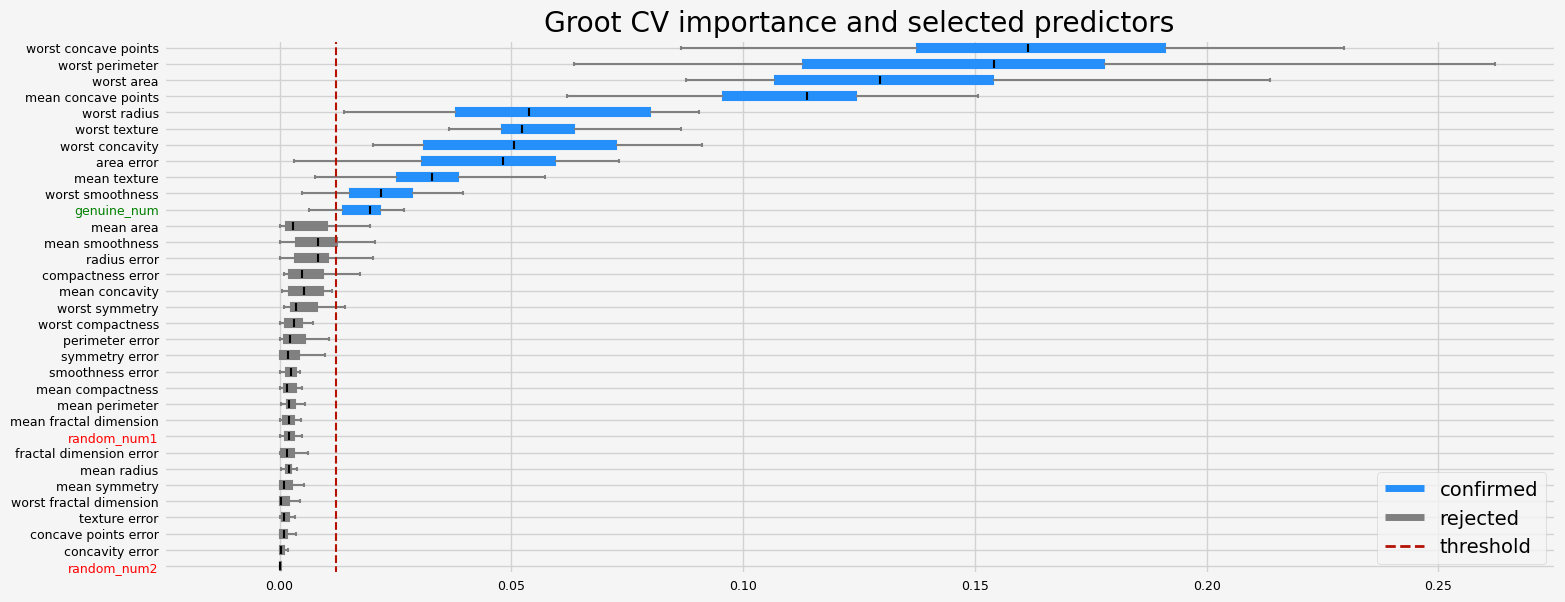
CPU times: user 23.9 s, sys: 2.21 s, total: 26.2 s
Wall time: 14.2 s
Filtered predictors#
[17]:
%%time
# be sure to use the same but non-fitted estimator
model = clone(model)
# GrootCV
feat_selector = arfsgroot.GrootCV(
objective="binary", cutoff=1, n_folds=5, n_iter=5, silent=True
)
feat_selector.fit(X_filtered, y, sample_weight=None)
print(f"The selected features: {feat_selector.get_feature_names_out()}")
print(f"The agnostic ranking: {feat_selector.ranking_}")
print(f"The naive ranking: {feat_selector.ranking_absolutes_}")
fig = feat_selector.plot_importance(n_feat_per_inch=5)
# highlight synthetic random variable
fig = highlight_tick(figure=fig, str_match="random")
fig = highlight_tick(figure=fig, str_match="genuine", color="green")
plt.show()
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[35] training's binary_logloss: 0.0459106 valid_1's binary_logloss: 0.262147
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[57] training's binary_logloss: 0.0115689 valid_1's binary_logloss: 0.172218
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[53] training's binary_logloss: 0.0168235 valid_1's binary_logloss: 0.0923885
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[50] training's binary_logloss: 0.0180443 valid_1's binary_logloss: 0.111598
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[104] training's binary_logloss: 0.000748065 valid_1's binary_logloss: 0.0294007
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[93] training's binary_logloss: 0.00114132 valid_1's binary_logloss: 0.0910524
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[43] training's binary_logloss: 0.0270845 valid_1's binary_logloss: 0.123796
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[71] training's binary_logloss: 0.00535761 valid_1's binary_logloss: 0.0782462
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[95] training's binary_logloss: 0.00116691 valid_1's binary_logloss: 0.0939008
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[34] training's binary_logloss: 0.0461312 valid_1's binary_logloss: 0.214626
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[51] training's binary_logloss: 0.0159229 valid_1's binary_logloss: 0.213906
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[76] training's binary_logloss: 0.00394837 valid_1's binary_logloss: 0.0989128
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[78] training's binary_logloss: 0.00363591 valid_1's binary_logloss: 0.0749228
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[49] training's binary_logloss: 0.0202799 valid_1's binary_logloss: 0.122675
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[39] training's binary_logloss: 0.0360213 valid_1's binary_logloss: 0.150868
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[46] training's binary_logloss: 0.0224482 valid_1's binary_logloss: 0.179054
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[68] training's binary_logloss: 0.00673935 valid_1's binary_logloss: 0.0768377
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[55] training's binary_logloss: 0.0128773 valid_1's binary_logloss: 0.116759
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[40] training's binary_logloss: 0.0332381 valid_1's binary_logloss: 0.125759
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[77] training's binary_logloss: 0.00328565 valid_1's binary_logloss: 0.111773
Training until validation scores don't improve for 20 rounds
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Early stopping, best iteration is:
[42] training's binary_logloss: 0.0315132 valid_1's binary_logloss: 0.148611
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[56] training's binary_logloss: 0.012564 valid_1's binary_logloss: 0.165237
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[68] training's binary_logloss: 0.00570134 valid_1's binary_logloss: 0.142653
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[54] training's binary_logloss: 0.0122192 valid_1's binary_logloss: 0.137096
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(
Training until validation scores don't improve for 20 rounds
Early stopping, best iteration is:
[90] training's binary_logloss: 0.00165684 valid_1's binary_logloss: 0.053699
The selected features: ['mean texture' 'mean area' 'area error' 'concavity error'
'symmetry error' 'worst smoothness' 'worst symmetry'
'worst fractal dimension' 'genuine_num']
The agnostic ranking: [2 2 1 1 2 1 2 2 1 2 2 2 1 1 2]
The naive ranking: ['ShadowVar2', 'ShadowVar7', 'ShadowVar9', 'ShadowVar13', 'ShadowVar6', 'ShadowVar12', 'ShadowVar4', 'ShadowVar15', 'ShadowVar8', 'ShadowVar10', 'ShadowVar1', 'ShadowVar3', 'ShadowVar5', 'ShadowVar11', 'ShadowVar14']
/home/bsatom/Documents/arfs_test_nbs/arfsuv/lib/python3.12/site-packages/shap/explainers/_tree.py:544: UserWarning: LightGBM binary classifier with TreeExplainer shap values output has changed to a list of ndarray
warnings.warn(

CPU times: user 15.6 s, sys: 1.2 s, total: 16.8 s
Wall time: 7.53 s
With GrootCV, same conclusion: the variability is much smaller (smaller confidence interval) when the collinear predictors are filtered out.